Feature Scaling In Machine Learning!

Feature Scaling is a technique of bringing down the values of all the independent features of our dataset on the same scale. Feature scaling helps to do calculations in algorithms very quickly. It is the important stage of data preprocessing.
If
we don't do feature scaling then the machine learning model gives
higher weightage to higher values and lower weightage to lower values.
Also, takes a lot of time for training the machine learning model.After doing feature scaling, we can conveniently train our models and draw predictions.
Types of Feature Scaling
- Normalization
Normalization is a scaling technique in which the values are rescaled between the range 0 to 1.

To normalize our data, we need to import MinMaxScalar from the Sci-Kit learn library and apply it to our dataset. After applying the MinMaxScalar, the minimum value will be zero and the maximum value will be one.
2. Standardization
Standardization is another scaling technique in which the mean will be equal to zero and the standard deviation equal to one.
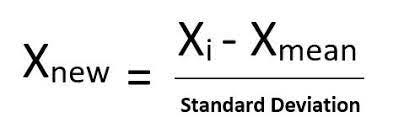
To standardize our data, we need to import StandardScalar from the Sci-Kit learn library and apply it to our dataset.
3. Robust Scalar
Robust scaling is one of the best scaling techniques when we have outliers present in our dataset. It scales the data accordingly to the interquartile range (IQR = 75 Quartile — 25 Quartile).

The interquartile range is the middle range where most of the data points exist.
4. Gaussian Transformation
When our dataset doesn't follow Gaussian/Normal distribution (Bell Curve) then we used Gaussian transformation.
Let's see different types of Gaussian Transformation,
i ) Logarithmic Transformation
dataset['Feature_Log'] = np.log(dataset[‘Feature’])ii ) Reciprocal Transformation
dataset['Feature_Reci'] = 1 / dataset[‘Feature’]iii ) Square Root Transformation
dataset['Feature_Sqrrt'] = dataset[‘Feature’]**(1/2)iv ) Exponential Transformation
dataset['Feature_Expo'] = dataset[‘Feature’]**(1/1.2)v ) Box-Cox Transformation
dataset['Feature_BC'] , Parameters = stat.boxcox(dataset['Feature'])Now let's see some questions,
Frequently Asked Questions!
Q. What is Feature Scaling?
Feature Scaling is a technique to normalize/standardize the independent features present in the dataset in a fixed range.
Q. Why Feature Scaling?
Some machine learning algorithms are sensitive, they work on distance formulas and use gradient descent as an optimizer. Having values on the same scales helps gradient descent to reach global minima smoothly. For example, Logistic regression, Support Vector Machine, K Nearest Neighbours, K-Means…
Q. When to used Feature Scaling?
We have to use when the range of independent features varying on different different scales.
Q. What are the advantages of using feature scaling?
- Makes training faster.
- Improves the performance.
Conclusions:
Feature scaling is an essential step in Machine Learning.
Comments
Post a Comment